

By Samantha Levin, Curator of Digital Assets
The Fashion Institute of Technology’s Special Collections and College Archives (SPARC) is a unique repository. Housed within the college’s library, it holds a number of rare and fragile items, which are carefully stored, organized, and described in detail to ensure that they will last for a long time, and are easily accessible to researchers.
SPARC certainly holds quite a bit of physical items including books, periodicals, prints, artwork, video cassettes, as well as a few objects here and there, but it also has a growing collection of digital items. The majority of those digital files are images digitized from the physical collection, some of which are viewable online in a platform called SPARC Digital, however it has been collecting more and more of what we call born-digital items. “Born-digital” describes something that was created using digital tools. Emails are born-digital, and, just like paper letters, we should be preserving them for the future. All the images you shoot using your smartphone are also born-digital. You can print them out, but their lives start off in digital form instead of having been shot on ye olde-timey film. There are quite a few tools out there that create born-digital content that range from the common examples just described to super-sophisticated tools such as Computer Aided Design software, video game engines, and more.
Websites fall under that born-digital category, and hold material that will be important for researchers in the future. Websites are complex creations that are composed of a lot of different kinds of digital content, including text, imagery, video, audio, and more. They often contain dynamic media that requires user participation, such as online games, forums, or net art.
Web pages are very ephemeral, which means that they change frequently and are difficult for archives to preserve. Data published online can change over time, be removed entirely, or become unreadable as web software becomes more sophisticated. Web archiving involves capturing snapshots of web pages to ensure the information and media they contain is preserved in an archive for future researchers, historians, and the public before they change. Web archivists use web crawler software, such as Archive-it as mentioned above, to do this work.
Many archives around the world have implemented web archiving programs that endeavor to preserve various kinds of websites before they’re lost and forgotten. You’ve probably heard of the Internet Archive. It has been preserving web pages since the mid-1990s, which is why we can take a look at what FIT’s website used to look like in 1997.

The Frick Museum runs a web archive of New York-based visual arts websites, the Cornell University Library keeps a web archive of Digital Art, and LIM College has a web archive that covers the business of fashion. There are many world governments that have robust web archiving programs intent on retaining what they deem to be important for their country’s historical record. This includes the United States’ own Library of Congress’ impressive web archiving work. While the Library of Congress does preserve quite a lot of web material, there are archivists who are greatly concerned with what information does not get preserved, especially as each presidential administration takes over from the previous one, often changing what government information is made publicly available online. Web archivists often work to preserve our government’s various web pages before they are irrevocably changed. The Environmental Protection Agency, for example, published an archived version of its website before the Trump administration took over in 2017. The information published on it is old, but retains concerns that the prior administration considered to be urgent, and ensures that those concerns are available to the public.
Preserving and providing access to historical information is crucial, so last year SPARC began archiving the FIT website in order to begin preserving a legacy of information and media that the college’s students, faculty, and staff have created and published there. Using software called Archive-it, SPARC has been capturing as much content as possible, which can now be viewed online. In many cases, the material on the FIT website that is getting preserved is pretty basic information about the school, such as directions on how to apply for financial aid for example, but there’s also unique content in there that only exists online. Blog posts, embedded social media posts, news, and various other media may exist in draft form in someone’s google drive somewhere, but their final published presence in the context of the FIT website is important to retain in order to remember what FIT was about at the moment the content was published.

While the Internet Archive has preserved some of the FIT website over the past few decades without our help, if you browse through the archived pages of the FIT website using the Wayback Machine, you’ll get to see how the college presented itself to the public over the years, as well as notice that there are a lot of elements that didn’t get captured. In many cases, entire pages are missing.
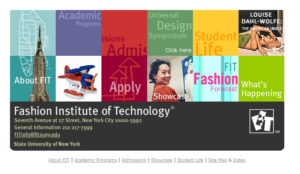
SPARC’s web archive project has ensured that more of the FIT website’s various iterations will be preserved. This is especially important in a year when so much traumatic change has been taking place, and so much of what FIT is creating and publishing has gone online. SPARC hopes to expand this web archiving program in the future to include content published online by entities in the fashion industry as well as other professions that FIT is connected to via its curriculum, but for now it focuses on FIT’s home turf.
It’s common to stumble upon dead links while browsing the web, or losing published work when a publisher redesigns their website or shuts down. Anyone who has experienced frustration from such issues knows the need for web archives. Anyone who relies upon the internet for any reason might want to consider doing their own web archiving work to preserve web pages that they consider valuable to them or to communities they support. To learn more about how web archiving works, look through the following resources:
Web archiving tools:
- The Internet Archive’s “Save Page Now” feature allows users to archive web pages making them viewable via a tool called the Wayback Machine
- Create a web archive using Conifer or Webrecorder
Web archive projects to explore:
- New York Art Resources Consortium (The Frick, MoMA, and Brooklyn Museum) archives of New York-based visual art websites
- Archiveteam
- Archive-it
- US Library of Congress’ Web Archiving Program
- LIM College web archive, 2009-2010
Dig deeper – learn more about how and why archivists are preserving the web: